Inteligentne techniki analizy danych
Aleksander Astel
Nieustanny wzrost ilości problemów badawczych powiązany ze wzrostem komplikacji obiektów badań wymusza konieczność stosowania wyrafinowanych technik analizy danych. W efekcie znacznego przyrostu mocy obliczeniowej współczesnych komputerów, w ciągu kilku ostatnich dekad ogromną popularność zyskały inteligentne techniki analizy danych, w których zaimplementowano algorytmy sieci neuronowych [1-4].
Sztuczne sieci neuronowe (ang.: Artificial Neural Networks) można traktować jako nowoczesne systemy obliczeniowe, które umożliwiają przetwarzanie informacji wzorując się na zjawiskach zachodzących w mózgu człowieka. Informacje wprowadzane do sieci mają charakter danych numerycznych, na podstawie których działanie sieci może odzwierciedlać działanie modelu o zupełnie nieznanej charakterystyce [5]. Dostosowanie sieci neuronowej do rozwiązywania określonego zadania odbywa się poprzez jej uczenie przy użyciu typowych pobudzeń i odpowiadających im pożądanych reakcji, a nie poprzez sprecyzowanie algorytmu i zapisanie go w postaci programu, jak w przypadku stosowania tradycyjnych metod modelowania. W efekcie sieć neuronowa tworzy model zjawiska lecz nie jest możliwe jednoznaczne określenie jego postaci. Ponadto, trudno udzielić jednoznacznej odpowiedzi na pytanie, czy konkretna, wyuczona sieć neuronowa w sposób rzeczywisty rozwiązuje problem czy tylko tworzy pewien algorytm, pozwalający jednak uzyskać prawidłowe wyniki [6]. Główne obszary zastosowań algorytmów sieci neuronowych to [7-12]:
- prognozowanie (przewidywanie wartości zmiennej na podstawie jej wartości wcześniejszej i innych czynników);
- aproksymacja w przestrzeni (poszukiwanie wartości pewnej zmiennej w przestrzeni na podstawie znanych wartości zmiennych w kilku punktach);
- klasyfikacja (na podstawie charakterystyki przedmiotu badań sztuczna sieć neuronowa określa, do jakiej kategorii on należy (m.in. rozpoznawanie pisma, cyfr lub obrazów));
- filtrowanie sygnałów;
- kompresja obrazu czy dźwięku;
- sterowanie układami dynamicznymi.
Algorytm samoorganizujących się map (ang.: self-organizing maps, SOM), lub nazywany inaczej samoorganizującym odwzorowaniem cech (ang.: self-organizing feature map, SOFM), opracowany w 1982 przez Teuvo Kohonena [13] to jeden z najbardziej zaawansowanych modeli sieci neuronowych, wykorzystywanych w wielu różnorodnych dziedzinach nauki, z których przykładowo można wymienić:
- klasyfikację i analizę danych pochodzących z monitoringu środowiskowego [14,15];
- klasyfikację sejsmofacjalną [16];
- klasyfikację próbek węgla kamiennego [17];
- analizę ekonometryczną [18];
- przetwarzanie danych ankietowych [19];
- organizację zasobów dokumentów tekstowych w odpowiedzi na zapytanie sformuło-wane w wyszukiwarce [20,21].
W zależności od obszaru zastosowania algorytm sieci Kohonena niejednokrotnie modyfikowano. Biorąc pod uwagę aplikacje dotyczące organizacji zasobów dokumentów tekstowych stosuje się mapy dla szybko rosnących zbiorów [21] (ang.: growing SOM, GSOM), mapy dla zbiorów o zmieniającej się hierarchii taksonomii (ang.: growing hierarchical SOM, GH-SOM), mapy wykorzystujące cechy rzadkie dokumentów (ang.: scalable SOM, SSOM), mapy wyszukujące słowa pasujące tematycznie [21] (ang.: LABEL-SOM) czy też analizujące częstotliwość występowania słów określających szukany termin [22-24] (ang.: WEBSOM). Należy jednak podkreślić, że sumaryczna liczba modyfikacji pier-wotnego algorytmu SOM jest znacznie większa i uzależniona od specyfiki określonej dziedziny prowadzenia badań.
Zastosowanie algorytmu SOM jest zasadne wszędzie tam, gdzie występuje potrzeba odwzo-rowania przestrzeni wielowymiarowej na płaszczyźnie. W toku jednej analizy możliwe jest wykrycie ewentualnych skupisk (grup podobieństwa) w zbiorze przetwarzanych danych jak również dokonanie odwzorowania cech wielowymiarowego sygnału wejściowego o złożonej strukturze na płaszczyźnie. W trakcie wykrywania skupisk w danych parametry sieci ulęgają modyfikacjom, co określa się często zdolnością do samoorganizacji. Dzięki zdolności do sa-moorganizacji mapy Kohonena umożliwiają adaptację do wcześniej nieznanych danych su-rowych, o których niewiele wiadomo. To sprawia, że w zasadzie działania SOM wykazują znaczne podobieństwo do ludzkiego mózgu. W obu przypadkach nie definiuje się określo-nych wzorców, a analiza danych odbywa się w procesie uczenia połączonego z normalnym funkcjonowaniem. Najważniejszą cechą algorytmu jest to, że nieliniowa relacja między obiektami zostaje zachowana a obiekty wykazujące wysoki stopień podobieństwa lokowane są na mapie blisko siebie. Dodatkowymi, niekwestionowanymi zaletami stosowania algoryt-mu SOM w analizie danych są: brak wymogu zgodności rozkładu zmiennych z rozkładem normalnym, możliwość wykrywania trudnych do przewidzenia struktur podobieństwa w da-nych, stosunkowo duża odporność na występowanie braków danych, możliwość identyfikacji obiektów o cechach odbiegających oraz brak konieczności subiektywnej interwencji badacza. Tę cechę często określa się terminem nauczania bez nauczyciela lub nauczaniem bez nadzoru (ang.: unsupervised learning). Ponadto, w większości przypadków, szczególnie tych związa-nych z klasyfikacją i analizą danych pochodzących z monitoringu środowiskowego, sieci SOM można efektywnie zastosować bez konieczności dysponowania zbiorami uczącymi i testującymi.
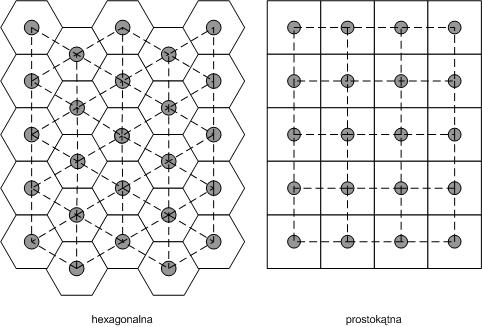
Funkcjonowanie samoorganizujących się map przebiega w trzech etapach. Pierwszy polega na tworzeniu ogólnej struktury mapy, drugi na trenowaniu sieci, w którym ustala się właściwa topologia mapy, natomiast trzeci to klasyfikacja. Mapa Kohonena to dwuwymiarowa macierz neuronów (jednostek wirtualnych) pobudzanych przez sygnały wejściowe, której rozdziel-czość jest ściśle związana z sumaryczną ilością danych surowych. Aby możliwe było graficz-ne zaprezentowanie dwuwymiarowej struktury mapy stosuje się siatki hexagonalne i prosto-kątne, przy czym hexagonalne nie faworyzują żadnego z kierunków, gdyż w każdym z nich odległości pomiędzy neuronami warstwy wyjściowej są równe. W aplikacji zaproponowanej przez Vesanto [25] dedykowanej środowisku Matlab® rozdzielczość mapy wyznacza się z równania n= . Przykładowo, gdy n=60 to rozdzielczość mapy może wynosić 5×8. Na rysunku 1 przedstawiono przykładowe siatki stosowane do odwzorowania struktury danych wejściowych.
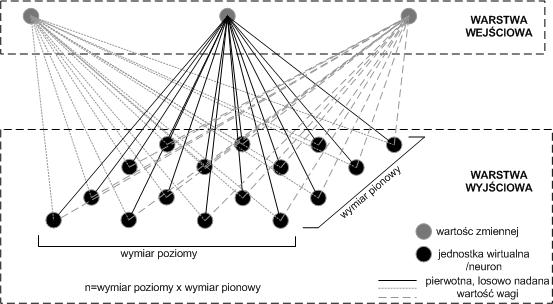
Rys. 1. Przykłady siatek stosowanych w technice SOM do odwzorowania struktury danych wejściowych
Sygnały wejściowe (dane) „rzutowane” są na płaszczyznę sieci neuronów z uwzględnieniem losowo nadanej wartości wagi dla każdego wyniku. W efekcie uzyskuje się macierz wag, na podstawie której następuje odwzorowanie pierwotnej struktury danych w nowej, zredukowa-nej strukturze jednostek wirtualnych (neuronów). Najczęściej, w algorytmach dedykowanych określonemu środowisku obliczeniowemu (np. Matlab®) przed tworzeniem finalnej struktury mapy dane ulegają normalizacji i standaryzacji. W ten sposób wyniki wykazujące wzajemne podobieństwo zmienności w zakresie rozpatrywanych cech będą w najwyższym stopniu wpływać na neurony zlokalizowane blisko siebie. Na rys. 2 przedstawiono dwuwymiarową strukturę mapy neuronów charakterystyczną dla sieci typu SOM.
Rys. 2. Dwuwymiarowa struktura mapy neuronów charakterystyczna dla samoorganizujących się map Kohonena
Na etapie trenowania, czyli tworzenia finalnej topologii mapy sieć ulega pobudzeniu losowo wybranym wektorem wejściowym X i na drodze współzawodnictwa wygrywa ten neuron (jednostka wirtualna), której wagi najmniej różnią się od odpowiednich składowych wektora wejściowego. Często, zwycięski neuron określa się terminem jednostki najlepszego dopasowania (ang.: Best Matching Unit, BMU). Dla zwycięskiego neuronu jak również dla neuronów zlokalizowanych w najbliższym sąsiedztwie zestaw pierwotnie losowo nadanych wag ulega modyfikacji zgodnie z regułami adaptacji opisanymi szczegółowo przez Kohonena [26], które uwzględniają współczynnik uczenia każdego neuronu oraz odległość względem wektora X, uwzględnioną przez kształt funkcji sąsiedztwa. Do wyznaczania zasięgu najbliższego sąsiedztwa stosuję się funkcje o różnych rozkładach (np. rozkład Gaussa; rozkład prostokątny). W efekcie wartość wag zwycięskiego neuronu, jak również neuronów zlokalizowanych najbliżej zwycięzcy, ulegają najbardziej istotnym modyfikacjom. Przy sąsiedztwie gaussowskim stopień adaptacji jest zróżnicowany w przeciwieństwie do sąsiedztwa prostokątnego, gdzie każdy neuron podlega adaptacji w tym samym stopniu. Sąsiedztwo gaussowskie jest bardziej precyzyjne i prowadzi do lepszych rezultatów uczenia oraz lepszej organizacji sieci [27]. Przedstawiony opis dowodzi, że algorytm Teuvo Kohonena przeprowadza uczenie bez nadzoru, czyli nie porównuje otrzymanych rezultatów uczenia z jakimkolwiek zbiorem wzorcowym oczekiwanych wyników dla określonego zespołu danych uczących [17]. Na rys. 3 przedstawiono schematycznie sposób modyfikacji pierwotnej struktury mapy na etapie pobudzania losowo wybranym wektorem wejściowym X.
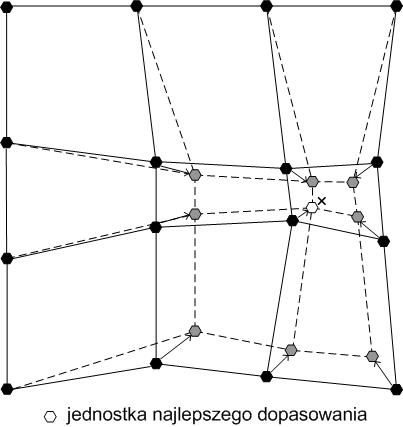
Rys. 3. Graficzna prezentacja sposobu modyfikacji wartości wag pierwotnego układu jedno-stek wirtualnych wymuszonych pobudzeniem wektorem wejściowym X.
Po zakończeniu treningu utworzona zostaje topologiczna mapa Kohonena, której dalsza analiza umożliwia wykrycie schematów podobieństwa w przestrzeni obiektów. Aby umożliwić wykrycie schematów podobieństwa w przestrzeni obiektów sieć musi być ponownie pobudzana losowo wybranymi wektorami wejściowymi Xi. W tym etapie pobudzania topologia sieci nie ulega dalszej modyfikacji a jego celem jest powiązanie obiektów występujących w danych surowych z konkretnymi fragmentami topologicznej mapy. Odbywa się to na zasadzie wyznaczenia liczby tzw. „trafień” czyli przypadków, dla których pojedynczy neuron najlepiej odwzorowuje strukturę danych wejściowych. Wiedza o ilości „trafień” przypadających na poszczególny neuron umożliwia dokonanie klasyfikacji przestrzeni obiektów według wybra-nego algorytmu np. metodą k-średnich.
Tytułem przykładu klasyfikacji i analizy danych pochodzących z monitoringu środowiskowe-go przedstawiono wyniki uzyskane podczas analizy wyników pomiarów stężeń wybranych jonów nieorganicznych (Cl-, NO3-, SO42-, NH4+, Na+, K+, Ca2+, Mg2+, Fe2+, Mn2+ i Zn2+) w próbkach wód opadowych zbieranych przez okres 60 miesięcy na terenie zlewni Potoku Dup-niańskiego w Beskidzie Śląskim. Pomiar stężeń poszczególnych analitów połączono z pomia-rem pH. Klasyfikację średnich miesięcznych poziomów stężeń analitów w próbkach opadów atmosferycznych przeprowadzono z wykorzystaniem techniki samoorganizujących się map Kohonena. Na rys. 4 przedstawiono zestaw map składowych dla poszczególnych zmiennych wprowadzonych do sieci podczas gdy na rys. 5 wizualizację topologii wytrenowanej mapy Kohonena.
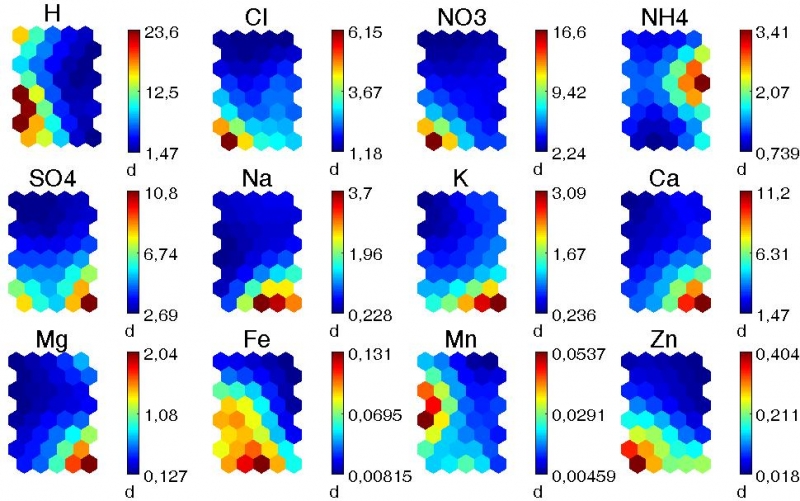
Rys. 4. Wizualizacja zależności/podobieństwa pomiędzy zmiennymi oznaczanymi w prób-kach wód opadowych zebranych w zlewni Potoku Dupniańskiego (d – zakres zmienności cechy)
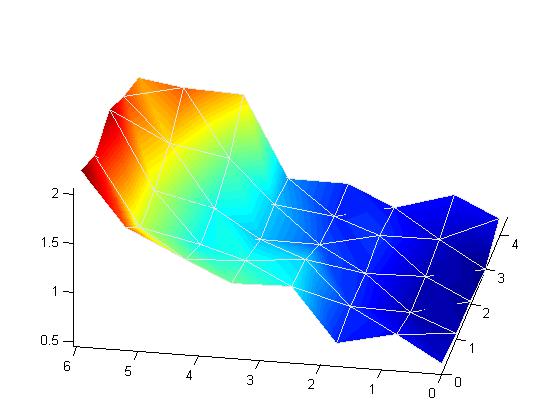
Rys. 5. Topologia kształtu wytrenowanej mapy Kohonena dla wyników pomiarów stężeń wy-branych jonów nieorganicznych w próbkach wód opadowych zbieranych na terenie zlewni Potoku Dupniańskiego w Beskidzie Śląskim
Wstępna, wizualna ocena układu kolorystyki map składowych pozwoliła zidentyfikować grupy zmiennych wykazujących wysokie podobieństwo. W przypadku układu hexagonalnych pól o kolorystyce charakterystycznej dla wysokiej zawartości analitu można stwierdzić, że jony Ca2+, Na+, K+, Mg2+ oraz SO42- wykazują wzajemne podobieństwo a co za tym idzie są wzajemnie skorelowane. Występowanie w opadach kationów zasadowych i ich możliwe połączenia z jonami SO42- do postaci soli: CaSO4, K2SO4, MgSO4 oraz Na2SO4 sprawia, że działanie kwasotwórcze jonów SO42- zostaje zneutralizowane. Dowodem na taką tezę odnośnie zachowania się metali wydawać się może fakt braku podobieństwa (a tym samym korelacji) pomiędzy mapami dla H+ i Ca2+, Na+, K+, Mg2+ oraz SO42-. Oznacza to, że niskie pH (przeliczone na stężenie jonów wodorowych) nie występuje w opadach w warunkach wysokiej zawartości kationów zasadowych oraz anionu siarczanowego. Analiza układu kolorystyki map sugeruje, że niskie pH a tym samym wysoko kwasotwórcze działanie opadów występuje symultanicznie z oznaczeniem w opadach wysokich wartości stężeń jonów Cl- i NO3-, dla których uzyskano podobną lokalizację obszarów wysokich wartości stężeń na mapie Kohonena. Warto podkreślić, że w tych przypadkach nie stwierdza się współobecności jonów neutralizujących. Pewne, choć wyraźnie niższe w porównaniu z jonami wymienionymi powyżej podobieństwo kolorystyki mapy występuje dla Fe2+, Mn2+ i Zn2+. Zanieczyszczenie opadów jonami metali ciężkich może być związane z wysoką emisją pyłów w rejonie Dolnego Śląska [28]. Wizualna ocena topologii kształtu wytrenowanej mapy Kohonena (Rysunek 5) dla wyników pomiarów stężeń wybranych jonów nieorganicznych w próbkach wód opadowych sugeruje występowanie co najmniej dwóch grup podobieństwa w zbiorze przetwarzanych danych. W związku z tym wyznaczono liczbę tzw. „trafień” czyli przypadków, dla których pojedynczy neuron najlepiej odwzorowuje strukturę danych wejściowych a następnie wykonano klasyfikację techniką k-średnich testując ilośc możliwych grup podobieństwa w zakresie od 2 do 6. Strukturę trafień, wartość indeksu Daviesa-Bouldina oraz podział mapy na podklasy przedstawiono na rys 6.
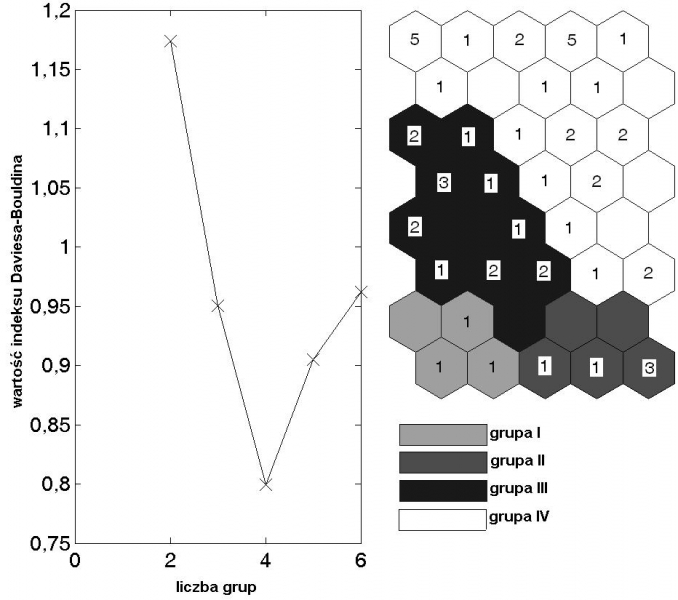
Rys. 6. Struktura liczby trafień czyli przypadków dla których pojedynczy neuron najlepiej odwzorowuje strukturę danych wejściowych, podział mapy na podklasy oraz wartość indeksu Daviesa-Bouldina
Na etapie testowania wyników klasyfikacji opartego na minimalnej wartości entropii układu (indeks Daviesa-Bouldina) ustalono, że w zbiorze przetwarzanych danych można wyodrębnić 4 podzbiory. Do poszczególnych grup zakwalifikowano odpowiednio 3 (grupa I), 5 (grupa II), 15 (grupa III) oraz 37 obiektów (grupa IV). Wynika z tego, że z danych wyodrębniono dwie niskoliczne oraz dwie liczne grupy wykazujące wzajemne podobieństwo. Zestawienie warto-ści średnich oznaczanych analitów z uwzględnieniem podziału na grupy uzyskane z analizy SOM umożliwiło zidentyfikowanie zmiennych odpowiedzialnych za klasyfikację jak również precyzyjną identyfikację próbek zakwalifikowanych do grup podobieństwa Dwie z trzech próbek zakwalifikowanych do grupy I pobrano w trakcie dwóch sąsiadujących miesięcy (wrzesień-październik 2000) co może świadczyć o tym, że rejon zlewni Potoku Dupniańskie-go znajdował się w owym czasie pod silnym wpływem lokalnego źródła zanieczyszczeń. Z kolei większość próbek zakwalifikowanych do grupy II pobrano w miesiącach, które powta-rzają się cyklicznie z roku na rok (sierpień 1999, 2000 i 2002) co może być efektem oddzia-ływania lokalnego źródła zanieczyszczeń lecz dodatkowo analiza wskazuje na możliwość cyklicznego oddziaływania źródła w warunkach powtarzalnych układów meteorologicznych. Próbki zakwalifikowane do licznych grup reprezentują ogólne schematy zmian występujące w przetwarzanych danych, w tym przypadku jest to sezonowość zmian z uwzględnieniem po-działu na sezon wegetacyjny i zimowy. W związku z tym, że celem niniejszej pracy jest ogól-ne przedstawienie techniki samoorganizujących się map Kohonena a także podkreślenie ich zalet głównie w odniesieniu do zadań klasyfikacyjnych pominięto szczegółową interpretację chemiczno-meteorologiczną poszczególnych klas. Szczegółową interpretację wyników przed-stawionych w przykładzie opisano w innych pracach [29,30]. Ogólnie można stwierdzić, że technika SOM jest efektywną techniką klasyfikacji na bazie której możliwe jest wykrycie zarówno tzw. punktów odbiegających (w odniesieniu do analityki środowiska oznacza to próbki znacznie odbiegające od innych pod względem zanieczyszczenia) jak i ogólnych po-dobieństw występujących w strukturze danych. Dodatkowa zaleta polega na tym, że klasyfi-kacja obiektów (w tym przypadku wyników oznaczeń wartości średnich zawartości analitów w próbkach wód opadowych) może obejmować jednocześnie identyfikację korelacji pomię-dzy zmiennymi jak również analizowanie fluktuacji wartości zmiennych w czasie.
Podsumowanie
Sieci Kohonena wykazują pod względem budowy i zasad funkcjonowania wysokie podobieństwo do ludzkiego mózgu. Podobieństwo to umożliwia efektywne zastosowanie sieci SOM do opracowania i klasyfikacji danych pochodzących z analiz praktycznie dowolnego obiektu badań. Umiejętność rozpoznawania naturalnych skupień (grup podobieństwa) występujących w danych i możliwości modyfikowania wewnętrznej kompozycji wag neuronów czyni z samoroganizujących się map Kohonena potężne narzędzie współczesnej analizy danych. Dodatkowe zalety, takie jak możliwość nauczania bez nadzoru, brak założeń dotyczących rozkładów analizowanych zmiennych, wyraźna rozdzielność funkcyjna warstwy wejściowej i wyjściowej, odporność na uszkodzenie niewielkiej liczby neuronów, odporność na występowanie niewielkiej ilości braków danych czy też zdolność do uogólniania sprawia, że mapy Kohonena zyskują coraz większą popularność i można się spodziewać, że w niedalekiej przyszłości zostaną zaimplementowane do najbardziej popularnych pakietów statystycznych. Wzrastająca popularność algorytmu Kohonena wynika także z możliwości przejrzystej wizualizacji wyników w formie topologicznej mapy podobieństwa w układzie obiekty/cechy jak również z możliwości nadania znaczenia rejonom mapy topologicznej na podstawie analizy konkretnych danych wejściowych.
Podziękowania
Niniejszy artykuł, stanowiący część cyklu „Chemometria jako wydajne narzędzie analizy da-nych środowiskowych” został opublikowany dzięki częściowemu wsparciu finansowemu w ramach projektu „Optymalizacja chemometrycznych technik eksploracji i modelowania wy-ników z monitoringu chemicznych zanieczyszczeń wybranych komponentów środowiska” (Nr decyzji 1439/T02/2007/32).
*Akademia Pomorska, Zakład Chemii Środowiskowej,
Instytut Biologii i Ochrony Środowiska, Słupsk, e-mail: astel@pap.edu.pl(link sends e-mail)
Literatura
[1] Tadeusiewicz R., Sieci neuronowe, Akademicka Oficyna Wydawnicza RM, Warszawa (1993)
[2] Żurada J., Barski M., Jędruch W., Sztuczne sieci neuronowe, Wydawnictwo Naukowe PWN, Waraszawa (1996)
[3] Korbicz J., Obuchowicz A., Uciński D., Sztuczne sieci neuronowe. Podstawy i zastosowa-nia, Akademicka Oficyna Wydawnicza PLJ, Warszawa (1994)
[4] Osowski S., Sieci neuronowe w ujęciu algorytmicznym, Wydawnictwo Naukowo-Techniczne, Warszawa (1996)
[5] Rutkowska D., Piliński M., Rutkowski L., Sieci neuronowe, algorytmy genetyczne i sys-temy rozmyte, Wydawnictwo Naukowe PWN, Łódź (1999)
[6] Einax J.W., Truckenbrodt D., Kampe O., River pollution data interpreted by means of chemometric methods, Michrochem. J., 58, 315-324 (1998)
[7] Zhang L., Wen L., Lu Y., Yang P., Quantitative fuzzy neural network for analytical determination, Anal. Chim. Acta, 468, 105-117 (2002)
[8] Magelseen G.R., Elling J.W., Chromatography pattern recognition of Aroclors using iterative probabilistic neural networks, J. Chrom. A, 775, 231-242 (1997)
[9] Ruisheng Z., Shuhui L., Mancang L., Zhide H., Neural network-molecular descriptors approach to the prediction of properties of alkenes, Computers Chem., 21 (5), 335-341 (1997)
[10] Tuovinen K., Kolenhmainen M., Paakkanen H., Determination and identification of pesticides from liquid matrices using ion mobility spectrometry, Anal. Chim. Acta, 429, 257-268 (2001)
[11] Ganadu M.L., Lubinu G., Tilocca A., Amendolia S.R., Spectroscopic identification and quantirative analysis of binary mixtures using artificial neural networks, Talanta, 44, 1901-1909 (1997)
[12] Kompany-Zareh M., Massoumi A., Pezeshk-Zadeh Sh., Simultaneous spectrophotometric determination of Fe and Ni with xylenol orange using principal component analysis and artificial neural networks in some industrial samples, Talanta, 48, 283-292 (1999)
[13] Kohonen T., Self-organiznig formation of topologically correct feature maps, Biol. Cybern., 43, 59-69, (1982)
[14] Astel A., Tsakovski S., Barbieri P.L., Simeonov V., A comparison of SOM classification approach with cluster analysis and PCA for large environmental data sets, Wat. Res. 41 (19), 4566-4578 (2007)
[15] Astel A., Tsakovski S., Simeonov V., Reisenhofer E., Piselli S., Barbieri P., Multivariate classification and modeling in surface water pollution estimation, Anal. Bioanal. Chem., (zaakceptowano do druku)
[16] Dzwinel K., Haber A., Krawiec D., Zastosowanie samoorganizujących sieci neurono-wych Kohonena w klasyfikacji sejsmofacjalnej (rejon Ujkowice-Batycze), Geologia, 4(32), 441-450 (2006)
[17] Bielak J., Zastosowanie sieci Kohonena do klasyfikacji próbek węgla kamiennego wg PN-54/G-97 002, [http://student.wszia.edu.pl/msi/pdf/sieck.pdf]
[18] Migdał Najman K., Najman K., Zastosowanie sieci neuronowej typu SOM do wyboru najatrakcyjniejszych spółek na WGPW w oparciu o wskaźniki analizy fundamentalnej, Sopot (2001)
[19] Grabska-Chrząstowska J., Fiedor M., Tucholska K., Weryfikacja działania sieci Kohone-na przetwarzajacych dane ankietowe zebrane wśród studentów krakowskiej AWF, Au-tomayka, 10 (3), 503-511 (2006)
[20] Rauber A., Merkl D., Dittenbach M., The growing hierachical self-organiznim map: exploratory analysis of high-dimensional data, IEEE Transactions on Neural Networks, 13 (6), 1331-1342, (2002)
[21] Rauber A., LabelSOM: On the labeling of self-organizing maps, Materiały konferencyjne IJCNN’99 International Joint Conference on Neural Networks, 5, 3527-3532, (1999)
[22] Honkela T., Kaski S., Kohonen T., Lagus K., Self-organizing maps of very large document collections: Justification for the WEBSOM method. W: Balderjahn I., Mathar R., Schader M., (Ed.), Classification, Data Analysis, and Data Highways, 245-252. Springer, Berlin (1998)
[23] Kaski S., Honkela T., Lagus K., Kohonen T., WEBSOM-self-organizing maps of document collections, Neurocomputing, 21, 101-117 (1998)
[24] Kaski S., Lagus K., Honkela T., Kohonen T., Statistical aspects of the WEBSOM system in organizing document collections, Comput. Sci. Stat., 29, 281-290, (1998)
[25] Vesanto J., Himberg J., Alhoniemi E., Parhankagas J., SOM Toolbox for Matlab 5, Report A57, 2000; http://www.cis.hut.fi/projects/somtoolbox/
[26] Kohonen T. Self-organizing maps. New York, Inc: Springer (1995)
[28] Małek S., Astel A., Throughfall chemistry in a spruce chronosequence in southern Poland, Env.Pollut., (zaakceptowano do druku)
[29] Astel A., Małek S., Sieci neuronowe jako narzędzie klasyfikacji próbek w analizie chro-matograficznej, Works&Studies,(70) 65-75 (2007)
[30] Astel A., Małek S., Multivariate modeling and classification of environmental n-way data from bulk precipitation quality control, J. Chemometrics (złożono do recenzji)